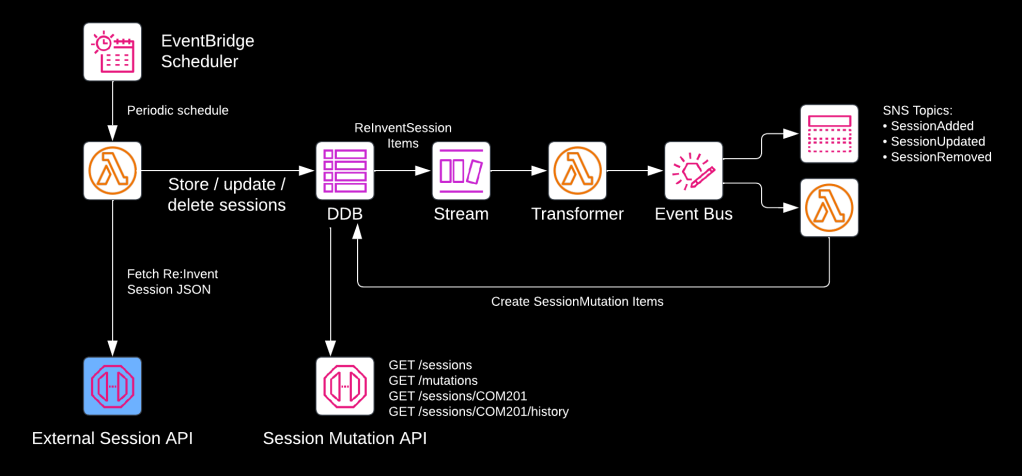
Re:Invent 2023 will take place the week after Thanksgiving (Monday November 27 to Friday December 1). If you’ve ever attended Re:Invent, you’ll know that keeping track of which sessions to attend is extremely difficult. To stay ahead of the game, I built a serverless Re:Invent session tracker. In this article we’ll highlight the architecture’s core design decisions.
⚠️ Unfortunately, the AWS Events team sent the following takedown notice ⚠️
> We were made aware of the version of the re:Invent schedule you made available at https://github.com/donkersgoed/reinvent-2023-session-fetcher. Per our AWS Site Terms, this is not an authorized use of AWS site content. We gate information that you made available here for registered attendees only, and would like to request that you remove the content.
The terms are clear, and there is no way I can keep the site online. All links to GitHub and the session tracker itself are now defunct.
The image above this post displays the architecture. In a nutshell, the application:
- Periodically fetches sessions from the official Re:Invent session catalog API
- Writes the sessions to DynamoDB
- Detects changes (additions, updates, and removals) of sessions
- Publishes events (SessionAdded, SessionUpdated, SessionRemoved) to EventBridge
- Stores the mutations in the DynamoDB table
- Publishes the mutations on SNS topics
- Makes the sessions and mutations publicly available via a REST API
The source code for the application can be found on GitHub: Re:Invent 2023 Session Fetcher.
In this article we’ll dive deeper into the following four architectural patterns / themes:
- Implementing the storage-first pattern with DynamoDB Streams
- Using EventBridge for event fan-out
- Public SNS topics
- API-supporting data duplication in DynamoDB
Implementing the storage-first pattern with DynamoDB Streams
Our Session Fetcher does what it says on the tin: it fetches sessions from the Re:Invent Session Catalogue. It downloads them, and:
- Stores the sessions in DynamoDB
- Emits events when sessions have been added, updated or removed
Generally, there are two ways of doing this, as displayed below.
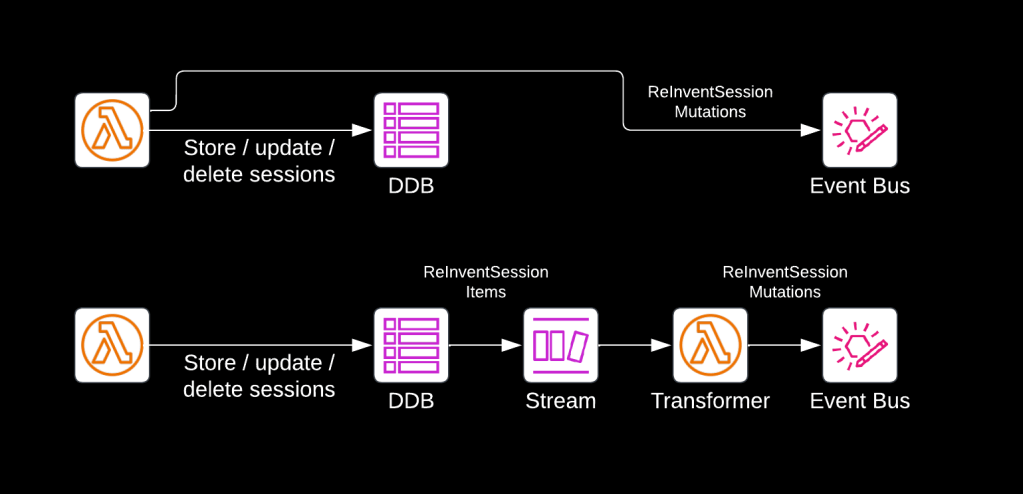
The Lambda function in the first solution fetches the sessions, uses the current contents of the DDB table to make a comparison, updates the items in the table, and then sends out an event for every change detected.
The Lambda function in the second solution also detects changes and updates the items in the table, but then it stops. The mutations of Re:Invent sessions (additions, updates and removals) are then automatically written to a DynamoDB stream, from where they are picked up by another Lambda function, which converts them to SessionAdded, SessionUpdated, and SessionRemoved events, and publishes those onto EventBridge.
The first solution might seem simpler, but it is an architecturally worse approach. To understand why, let’s look at the first solution and imagine this: the Lambda function writes an updated item to DynamoDB and then crashes, for whatever reason. The SessionUpdated event would never be published to EventBridge, leading to inconsistency: the data in the database no longer matches the events emitted. You could try to solve this by first emitting the event and then storing the data – but it would just lead to the opposite inconsistency (and duplicate events) when an unexpected failure occurs.
These problems are partly caused by not sticking to the single-responsibility principle: the Lambda function is responsible for both storing the sessions and emitting updates.
The second solution solves the risk of inconsistency by applying the storage-first pattern: the first Lambda function is only responsible for updating the DynamoDB table. If it fails, the function will simply try again at its next invocation. Only when the items are stored are they written to the stream, from where events are generated. This guarantees that events emitted always reflect the latest state in the database. The second Lambda function also adheres to the single responsibility principle: it is only responsible for reading events from the stream, transforming them and emitting them to EventBridge. If this function experiences a transient failure, it will automatically retry reading from the last stream checkpoint, adding additional resilience.
Conclusion: by applying the storage-first pattern we have made the solution more predicable, more resilient to failure, and easier to maintain.
Using EventBridge for event fan-out
The second architectural highlight is using EventBridge for event fan-out. The fan-out pattern simply describes receiving events from a single source of data (DynamoDB streams, in our case), and emitting those events to multiple destinations. In AWS, there are three core serverless services that support fan-out: SNS, EventBridge and (to a limited extent) Kinesis Data Streams, or KDS. We will leave the latter out of consideration, because KDS is mainly designed for high-throughput, sharded, ordered event streams, which is not what we need.
There are a few differences between SNS and EventBridge. The most important distinction is that EventBridge is a single event bus capable of transporting many event types, while SNS is designed to have a single topic per event type. Additionally, EventBridge is strongly aimed at internal traffic, while SNS can also deliver events to public email addresses, HTTPS endpoints and mobile push destinations. Inherently, EventBridge supports a limited amount of consumers while SNS supports millions of them.
The reason we chose EventBridge is because it allows for great versatility in our architecture. When we have more events to publish (say, NewSubscriber) we can simply publish them on the existing event bus – no additional infrastructure needed. Likewise, if we have a new use case (say, batching events for a daily digest), we can just consume the existing events from the bus. The built-in filtering and transformation features make building new integrations on top of EventBridge a breeze.
Conclusion: we use an EventBridge event bus as our central event messaging platform because it allows us to naturally decouple distinct application components, without requiring additional messaging infrastructure as our application grows.
Public SNS topics
The entire purpose of the Re:Invent Session Tracker is staying on top of changes to the session catalog. We can do this through a user interface (and in fact, I’m hosting one at https://reinvent23.l15d.com/mutations), but that’s a polling mechanism. Polling is inherently inefficient – you only see what is changed when you go out to look for it.
A more efficient system is based on push messaging: an email, an SMS, or a mobile push notification when a change is detected. The AWS technology that supports these patterns is Amazon’s Simple Notification Service, or SNS.
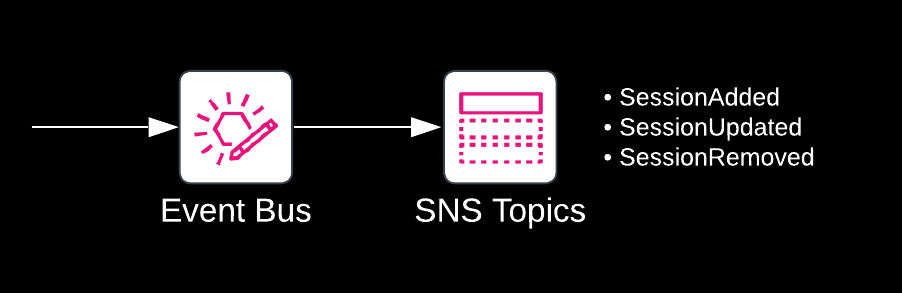
SNS supports seven integration types, allowing interested parties to receive updates to the session catalogue almost any way they like. SNS also supports public topics, which are available for anyone to subscribe to. The Re:Invent Session Tracker provides three public topics:
arn:aws:sns:eu-west-1:739178438747:SessionAddedarn:aws:sns:eu-west-1:739178438747:SessionUpdatedarn:aws:sns:eu-west-1:739178438747:SessionRemoved
You can login to any AWS account and add a subscription:
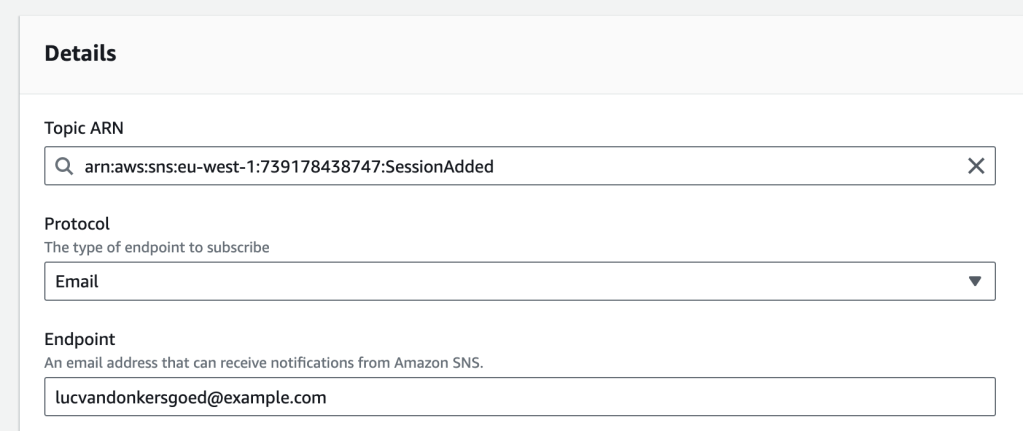
The screenshot above shows an email subscription, but you can also subscribe a Lambda function, SQS Queue or HTTPS endpoint to the updates, allowing you extend and build your own platform upon the Re:Invent Session Tracker.
I was inspired to offer public SNS endpoints by Amazon itself, who use them to publish changes to their IP ranges. See Subscribe to AWS Public IP Address Changes via Amazon SNS for more info.
Conclusion: while our internal messaging platform is based on EventBridge, SNS is the right service to use for public messaging. Consumers can manage their own subscriptions and integrate any way they like. SNS supports millions of subscribers per topic, so it can scale without effort. Public SNS topics can be used to build a safe and clear separation between producers and consumers.
API-supporting data duplication in DynamoDB
The Re:Invent Session Tracker uses DynamoDB single table design to store its data. When sessions are fetched from the Re:Invent session catalogue, they are indexed like this:

The PK, or PartitionKey, allows us to query all ReInventSessions. The SK, or SortKey, allows us to query for a specific session (e.g. ADM301) or all sessions in a given track (e.g. SK.beginsWith(ADM)).
Our Re:Invent Session API has four endpoints. They are publicly available at GET https://api.reinvent23.l15d.com/<endpoint>:
- /mutations – returns all changes to all sessions, chronologically ordered
- /sessions – returns all sessions
- /sessions/<session_id> – returns the details of a specific session
- /sessions/<session_id>/history – returns the history of a specific session
The data for endpoints 2 and 3 can be retrieved from the DynamoDB table with the index pattern shown above. Endpoint 2 would query PK.equals(ReInventSession) while endpoint 3 would query PK.equals(ReInventSession) and SK.equals(<session_id>). However, we have no efficient query solution (or even index design) for access patterns 1 and 4. So let’s solve that.
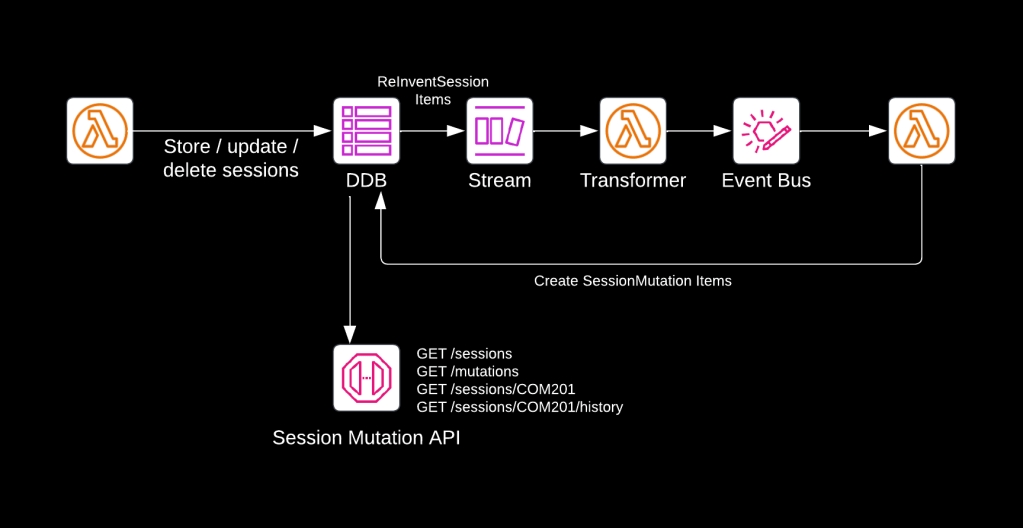
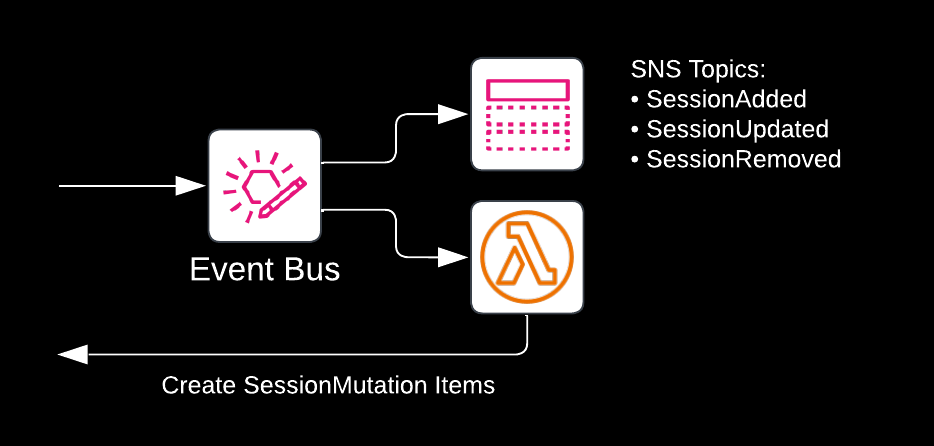
Keen-eyed readers will already have spotted the Lambda function consuming events from the EventBridge event bus on the right. The line back to DynamoDB says “Create SessionMutation Items”. This Lambda function uses the following EventBridge filter rule to make sure it receives the correct events:
"EventPattern": {
"detail-type": [
"SessionAdded",
"SessionUpdated",
"SessionRemoved"
],
"source": [
"ReInventSessionFetcher"
]
}
Every time the Lambda function is invoked with a new session mutation (added, updated, or removed), it writes two separate items to the DDB table, identified by their PK:
SessionMutation{session_id}#SessionMutation
In DynamoDB, the items look like this:
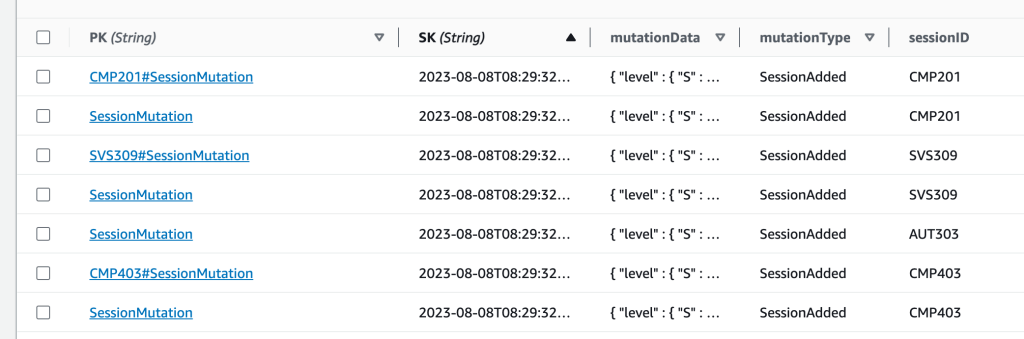
With these indexes we can fulfill the requirements for access patterns 1 and 4. To get all mutations, we simply query for PK.equals("SessionMutation"). To get all mutations for a single session, we query for PK.equals("<SessionID>#SessionMutation"). Every mutation item in the database contains a full copy, or snapshot, of the session at the time of the mutation. This allows us to build a reliable history of all changes to sessions, even though the root object, with PK: "ReInventSession" and SK: "<SessionID>", is always updated to reflect the latest state of the session.
Conclusion: a core truth in NoSQL databases, and DynamoDB in particular, is that you need to design your data model for its access patterns. In our case we have four different patterns, which we can efficiently handle with three item classes. Data duplication is used to have the session data available with every query type. The common duplication challenge of keeping all copies in sync does not apply here, because the duplicated data are immutable snapshots.
Conclusion
In this article we’ve explored a rather small serverless application. We’ve seen that even in limited-scope applications like this, there are many trade-offs to consider, services to choose from, and patterns to apply.
One particular shout-out goes to DynamoDB streams. I believe this service is underrated and underutilized in many solution architectures. As we’ve discussed in this article, it can be the driving force behind implementing the storage-first pattern, the single-responsibility principle, and DynamoDB data duplication.
I hope this page has provided a look at a day in the life of a solutions architect. It’s all about knowing the services available to you, weighing their pros and cons, and implementing time-proven patterns and principles. Designing a solution well will cost time and effort, but you’ll find that the product will be easier to build, maintain, operate, and evolve far into the future.
