
In computing, everything is a trade-off. This is not new or controversial. But what are we actually trading against each other? What are the pros and cons of our decisions? We commonly use trade-off models to answer these questions. This article will explore why the Serverless trade-off model might be different from other cloud architecture models and proposes a more fitting model instead.
The classic compute model
The classic compute trade-off model, for example used in the AWS Well-Architected Framework, posits cost, performance, and reliability in a trade-off triangle:
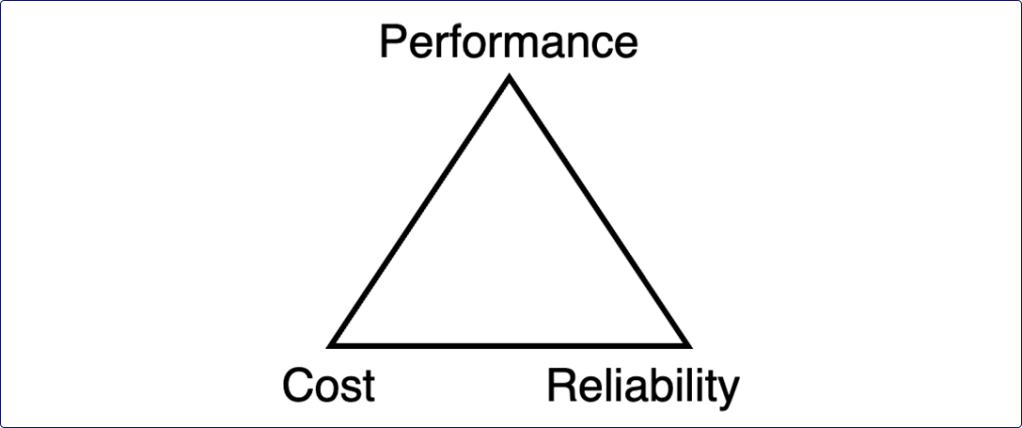
This model is called a trilemma – much like a dilemma, but with three components. The model’s nodes are in constant tension with each other. For example: you can optimize for cost, but it will negatively affect performance, reliability, or both. Or you might build a cost-effective and reliable system, but it won’t be performant. In classic cloud computing, these are the three base cases:
- Cost-effective and performant: a single large machine – not very reliable
- Cost-effective and reliable: multiple small machines – not very performant
- Performant and reliable: multiple large machines – not very cost-effective

The choices are not binary though: often you can trade slightly better cost efficiency for a little less reliability or performance, as shown in diagram 4. Which balance is best completely depends on your use case and context.
Trade-offs in Serverless
When choosing to use AWS Serverless in your cloud environments, you’re making a number of trade-off decisions too. These are not the same trade-offs as covered by the model above. Instead, they are:
- Commitment to lock-in to the AWS ecosystem. In return you get usage of their most mature services.
- Commitment to higher cost per execution. In return you get lower operational overhead.
- Commitment to higher complexity. In return you get highly available services.
- Commitment to strongly opinionated services. In return you get battle-proven patterns.
I’ve extensively written about these trade-offs in my blog post “When the shoulders of giants are offered, you’d do well to stand on them”.
Serverless characteristics
If you’ve chosen to use Serverless, you’ve already made a decision about the trade-offs listed above. In the following segment, I want to focus on two specific details: the Serverless compute model and the inherent reliability of natively distributed systems.
A limited compute model
In AWS Serverless you only have a few compute options: Lambda, Fargate, Step Functions, and some use-case specific services like Glue and CodeBuild. Looking at the Big 2 (Lambda and Fargate) you will find that they have very few performance dials to turn. You can choose the architecture (x86 or ARM), and the number of CPUs (including fractions of a vCPU). The big missing dial is clock speed, or single thread performance. Once you’re at one vCPU or above, the single-thread speed you’re getting is what you get. In other words: there is no vertical scaling. Instead your only option is horizontal scaling – either through more threads or more parallel instances.
Native reliability through distributed computing
So Serverless forces you to design for horizontal scaling. This is generally a good design principle anyway, because horizontal scaling is more adaptive, faster, and has a much higher scaling ceiling than vertical scaling. But there is more: horizontal scaling automatically translates to distributed computing, and distributed computing makes for inherently reliable systems. The failure of a single node in a large fleet is much less impactful than a single node running in isolation. Add some queueing and retry mechanisms in the mix – as Serverless architects generally will – and the impact of compute node failures is reduced to near-zero.
A new trilemma: cost, performance, and complexity
Because of Serverless’ limited compute model and native reliability, the classic compute trade-off model no longer applies. After all, how are you going to trade off reliability against cost, if reliability is a given?
Yet we still make decisions and trade-offs in our Serverless architectures. Sometimes we choose API Gateway, sometimes an Application Load Balancer. Sometimes we choose EventBridge, sometimes SNS or Kinesis Data Streams. How should we model these trade-offs so we can make better, more informed decisions about our architecture? What model should we use if the classic compute model no longer applies?

The answer is replacing the reliability property with complexity. Let me explain this with a common example: Aurora Serverless versus DynamoDB. Often DynamoDB will provide better and more predictable performance at higher cost-efficiency, but at the cost of complexity. Suddenly you need to manage complex data models in your application layer, you need to predict all your access patterns, and schema migrations are a headache. On the other hand a relational database is much easier to use and evolve, but it might have lower performance and higher cost. Please note that the exact opposite argument can also be made. In many cases Aurora will be more cost effective and performant. The truth completely depends on your context and use case.
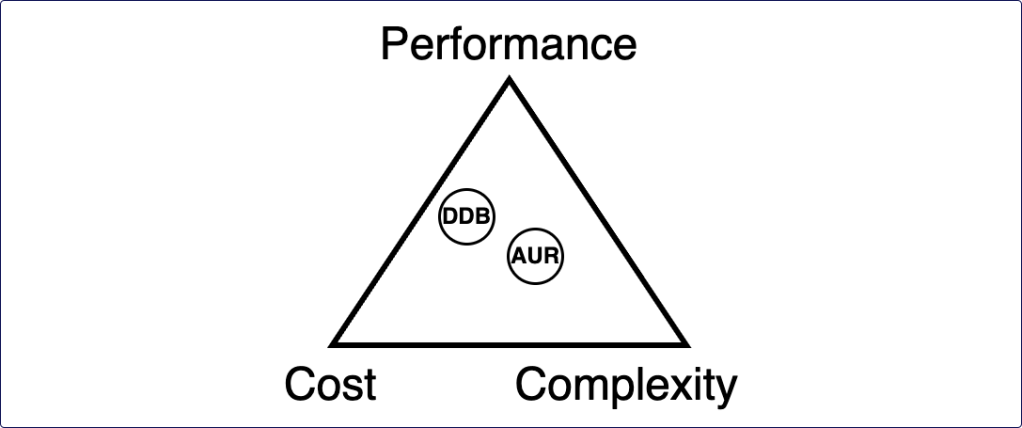
This brings us to how the model should be used. It is intended to help you make decisions, not to provide an all-knowing answer. To help you decide, you need to follow these three steps:
- Plot the competing solutions on the model. This isn’t exact science. The most important rule is that the solutions are correctly placed in relation to each other – more cost effective solutions should be more to the bottom left than more expensive solutions, more performant solutions should be higher than less performant ones.
- Define which properties are more highly valued by your team and application. Is cost more important than performance? Can you deal with more complexity to reduce cost? Defining business objectives and tenets (also known as guiding principles) for your application can help here.
- Decide and document. If you’ve followed steps one and two, the best decision should automatically emerge. If multiple solutions overlap they likely aren’t very different, and you can choose either one. Once you’ve made a decision, document it so others can understand your thought process in the future.
Performance in a limited compute model
After reading about Serverless’ limited compute model, you might be surprised to see performance as one of the trilemma’s properties. After all, at first glance we seem not to have much influence on it. If we look a little deeper, however, we will find that we can actually affect performance quite a bit. Generally performance can be expressed as latency: the time it takes to receive a response, the time it takes to complete a process, the time-until-first-byte, and various other delays in a system. Many design choices affect latency. For example, an EventBridge event bus takes more time to deliver a message than SNS, while Kinesis Data Streams (with enhanced fan-out) is even faster. But each solution also affects cost and complexity, which should be considered in the trade-off decision.
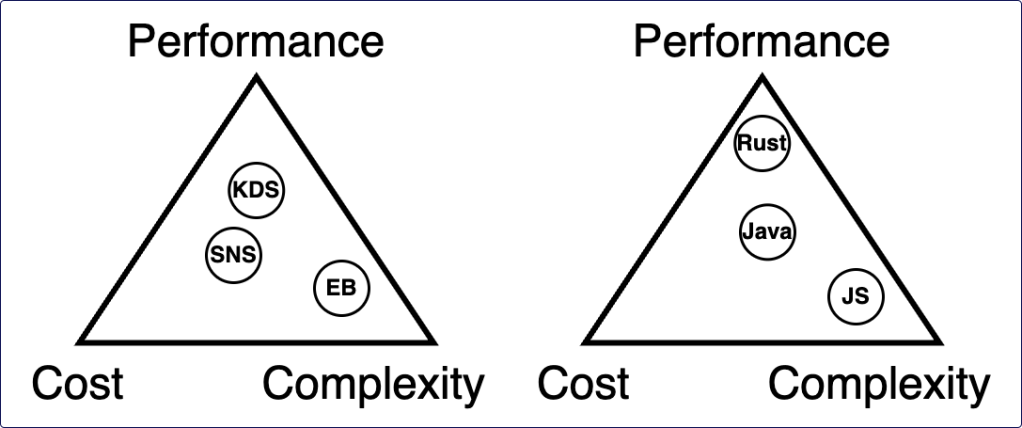
Another decision affecting performance is the programming language used in your Lambda functions. Java and C# use a virtual machine under the hood, which adversely affects cold starts but performs well after the initial boot. Rust and Go are compiled languages which result in near-zero cold starts, but require more complexity in the CI/CD process. Your team’s expertise in these languages will also influence how they rate on the complexity and cost scale – a team already fluent in Go will have an easier time deploying it than a Java-centric team, and retraining a team to use a new language can be expensive.
Changing contexts change the trade-off balance
After you have used the model to choose and implement a solution, your application and application context will continue to evolve. You might see an influx of users, new business requirements will emerge, your team will mature, and new technologies will become available. These changing contexts change the trade-off balance: a small team building a small application will prioritize cost, while a larger team delivering features to millions of users might prioritize higher performance or lower complexity. A message bus processing billions of events per day might be more cost effective on Kinesis, while a message bus processing dozens of messages per day might be a better fit for EventBridge. Jeremy Daly has a great keynote about this topic: “Elevate Your Cloud Workloads with Productized Patterns”. In this talk he explains there are multiple ways to implement a pattern, and which implementation you need depends on its context. He also says these implementations should be interchangeable, which perfectly aligns with the topics discussed in this article. My advice is to continue to review your architecture as it evolves and to revisit the Serverless trilemma when new frictions arise. You might find that the changed context demands a different implementation than before.
A real-world example
This article was inspired by a real-world problem. I maintain https://aws-news.com in my spare time. It is funded by sponsorships but I pay the AWS bill out of my own pocket. As such, cost effectiveness is the main business driver for my architectures. By the way: I’m always looking for sponsors. If you’re interested, check out my sponsors page!
Due to the nature of the platform, using a relational database is almost unavoidable. In my context the most cost effective RDS solution is Aurora Serverless, at least until Aurora DSQL becomes generally available. Since November 2024 Aurora Serverless supports scale-down-to-zero, which is great for dev and staging environments – it really helps drive down cost! However, the AWS News Feed polls for new articles every minute. To confirm an article isn’t already available in the database, it… checks the database. This way the database can never go to sleep, and scaling down to zero never happens. To solve this I added an Article Tracking Table in DynamoDB, which is a simple list of articles already imported. The periodic fetcher compares found articles against the table, and only when they aren’t found are they written to the relational database. This allows Aurora Serverless to hibernate about 50% of the week, which translates to real cost savings.
Of course, all these moving parts add complexity. There is a lot more to maintain and the architecture is more difficult to comprehend. But in the context of my wallet, this is a trade-off I am happy to make.
Conclusion
In software development every problem has many solutions, and deciding which is the best is never easy. It depends on the priorities and requirements of your business, application, and team. Mapping solutions along several axes will help you visualize their trade-offs, but choosing the right axes is a challenge in itself. The classic performance-cost-reliability trilemma does not fit Serverless architectures very well, but performance-cost-complexity might be a much better fit. It has helped me make impactful architectural decisions, and I hope it will help you too.
